Why teams choose the wrong approach
A common failure pattern:
Someone says “We need AI”
The team starts with a huge chatbot
It answers inconsistently, hallucinates, and can’t take actions safely
Then everyone loses confidence
Instead, start with a simple question:
What do we need from AI—knowledge, behavior, or action?
Because each one maps to a different solution.
1) Define the job: knowledge, behavior, or action?
A) Knowledge problems
Examples:
“What’s our refund policy?”
“How do I configure a loan product?”
“Which fields are required for KYC level 2?”
These require up-to-date internal docs. The model must be grounded in your current knowledge base.
✅ Best fit: RAG
B) Behavior problems
Examples:
“Always respond in a strict JSON schema”
“Write support replies in our tone”
“Classify tickets into 12 categories consistently”
These require consistency, not just information.
✅ Best fit: Fine-tuning (or structured prompting + evals)
C) Action problems
Examples:
“Create a support ticket”
“Update customer address”
“Generate a loan repayment schedule”
“Run a risk check and summarize it”
These require integration with your systems.
✅ Best fit: Tool calling (with permissions, approvals, and logging)
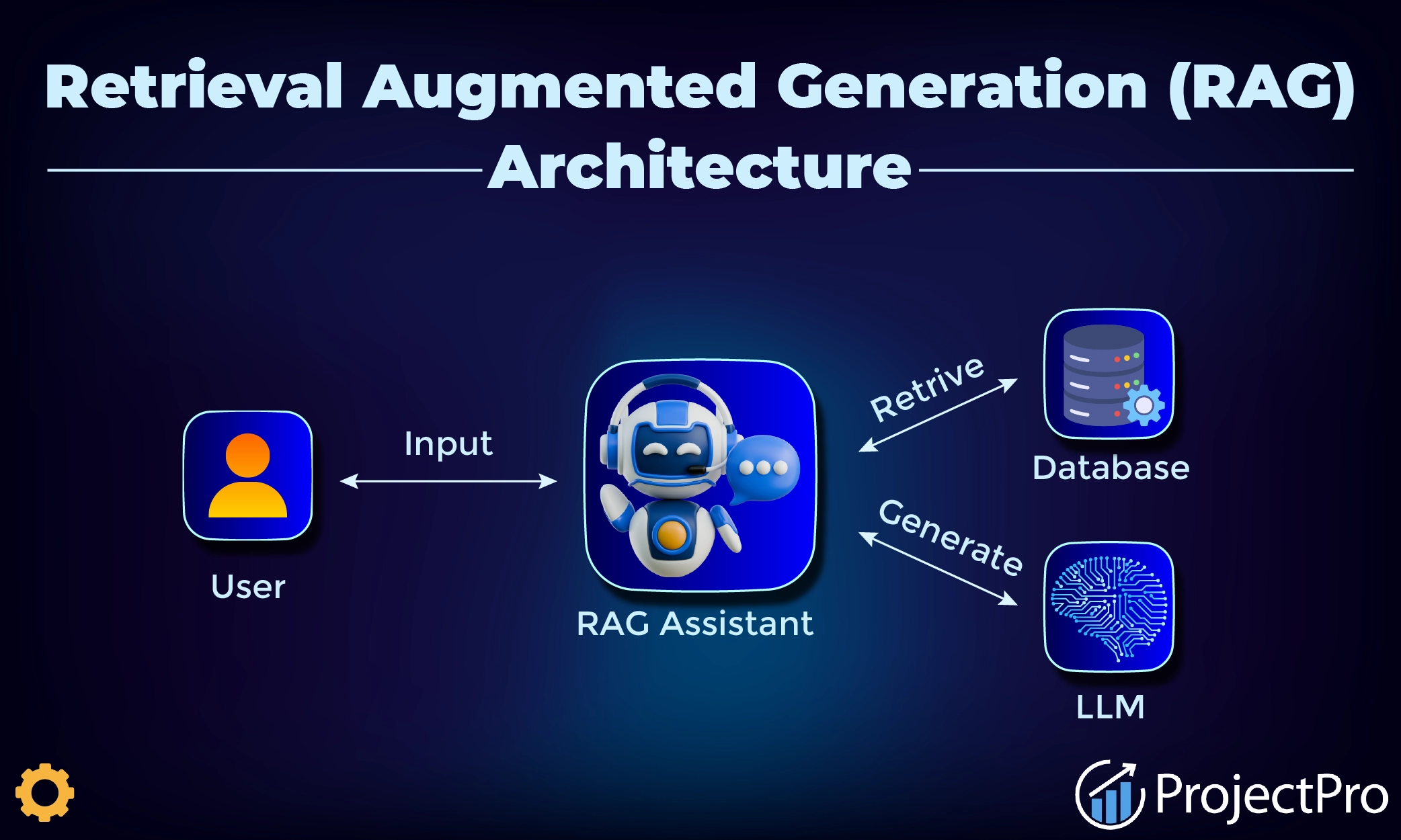
2) RAG: when you need fresh knowledge
RAG works by retrieving relevant chunks from your documents and providing them to the model as context.
When RAG is the best choice
docs change weekly/monthly
multiple teams own content
you need citations or “source-based” answers
you want tenant-specific knowledge (multi-tenant SaaS)
RAG implementation tips (practical)
Keep retrieval scoped (tenant/user permissions)
Chunk docs by meaning, not by characters only
Prefer smaller, high-quality sources over “dump everything”
Add “answer only from sources” behavior + refusal rules
Common RAG failure modes
poor chunking → irrelevant retrieval
no permission checks → sensitive data leakage
too many chunks → noisy context and bad answers
3) Fine-tuning: when you need consistent behavior
Fine-tuning shines when you want reliable patterns, style, or structured outputs.
When fine-tuning makes sense
you have repeatable examples (hundreds/thousands)
you want stable JSON outputs
you need consistent classification or extraction
you want shorter prompts and lower latency
What fine-tuning does NOT do
It does not “learn your latest policies” automatically
It won’t update when docs change unless you retrain
It does not replace tool permissions or audit logs
Think of fine-tuning as behavior calibration, not a knowledge base.
4) Tools: when AI must actually do things
Tools turn AI from “assistant” into “operator,” but they must be controlled.
Tool safety rules (minimum)
least privilege (tools can only do what’s necessary)
approval for risky actions (payments, exports, deletes)
strict schemas for tool inputs/outputs
logs + tracing for every tool call
Where tools shine
support workflows (ticketing, tagging, summarizing)
admin operations (generate reports, check status)
fintech workflows (draft decisions, summarize risk signals)
5) A simple decision matrix (copy)
Use this table logic in your team:
If the answer must reflect changing docs → RAG
If output format must be consistent → Fine-tuning
If the system must update data → Tools
If all three apply → start with RAG + Tools, then fine-tune later if needed
Recommended rollout path (lowest risk)
Phase 1: RAG assistant (read-only)
retrieval with citations
refusal rules
evaluation set (accuracy)
Phase 2: Add tools (restricted)
create drafts, not final actions
approvals for final actions
audit logs
Phase 3: Fine-tune for behavior
reduce prompt size
improve consistency
stabilize structured outputs
This path ships value early and reduces rework.
Common mistakes (and fixes)
Starting with fine-tuning without a dataset → begin with RAG + evals
Letting tools write directly → start with “drafts + approvals”
No measurement → track accuracy, cost, latency, and failure types
Treating RAG as “dump docs” → improve chunking + filtering
Closing
RAG, fine-tuning, and tools aren’t competing ideas—they solve different problems. When you match the approach to the real requirement, AI features become reliable, measurable, and easy to scale.
If you want, OSCORP can help you choose and implement the right architecture:
RAG pipeline design (chunking, permissions, citations)
safe tool calling (approvals, logging, schemas)
fine-tuning plan + evaluation harness


